

Normalisation et standardisation sous SAS
Théorie et mise en pratique de ces deux transformations
La normalisation et la standardisation des données sont des méthodes de mise
à l'échelle (scaling en anglais) que l'on applique communément en amont d'un
processus d'analyse ou d'un algorithme. L'objectif recherché est d'éliminer l'effet
d'unité qui pourrait donner mécaniquement plus de poids à un facteur qu'à un
autre.
Nous allons voir dans cet article en quoi elles consistent et quelle
est la différence entre ces méthodes.
Pourquoi vouloir transformer une variable ?
Que ce soit pour une problématique de régression ou de clustering, les données avec lesquelles nous sommes à même de travailler présentent la plupart du temps des unités diverses et variées. On peut citer par exemple le prix au mètre carré et la surface d'un appartement. Comment être sûr qu'un modèle n'accordera pas plus d'importance au premier, dont l'ordre de grandeur peut être de 100 voire 1000 fois plus grand que le second ?
Pour gommer cet effet que l'unité peut avoir sur l'influence d'un facteur sur une variable
d'intérêt plusieurs méthodes existent. Nous allons en voir trois :
- la normalisation par l'entendue, également appelé min max,
- la normalisation, dite robuste, centrée sur la médiane,
- la standardisation, qui consiste à centrer et réduire une variable sur sa moyenne et son écart-type.
Normaliser une variable
Normaliser une variable va consister à ramener celle-ci dans un intervalle [0..1] tout
simplement. Pour ce faire on applique la formule suivante :
$${x = \frac{X - min_{(X)}}{max_{(X)} - min_{(X)}}}$$
Comme vous le voyez, on effectue un déplacement de l'origine sur le minimum de la série puis on réduit en appliquant un rapport sur l'étendue de celle-ci, c'est à dire la différence entre le maximum et le minimum.
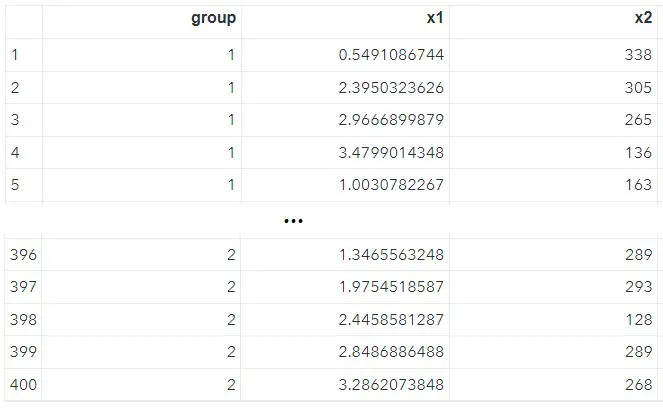
Illustrons ceci par un exemple très simple. Pour cela nous allons générer un dataset de quelques lignes comptant 3 variables numériques : un groupe, sur lequel nous reviendrons plus tard, une variable x1 dont la distribution suit une loi normale de paramètre (2.2, 1) et une variable x2 dont l'étendue couvre un intervalle [1..350] :
data df;
seed =2023;
call streaminit(seed);
do group = 1 to 2;
do i = 1 to 10;
x1 = rand ('normal', 2.2, 1);
x2 = rand('integer', 1, 350);
output;
end;
end;
drop seed i;
run;
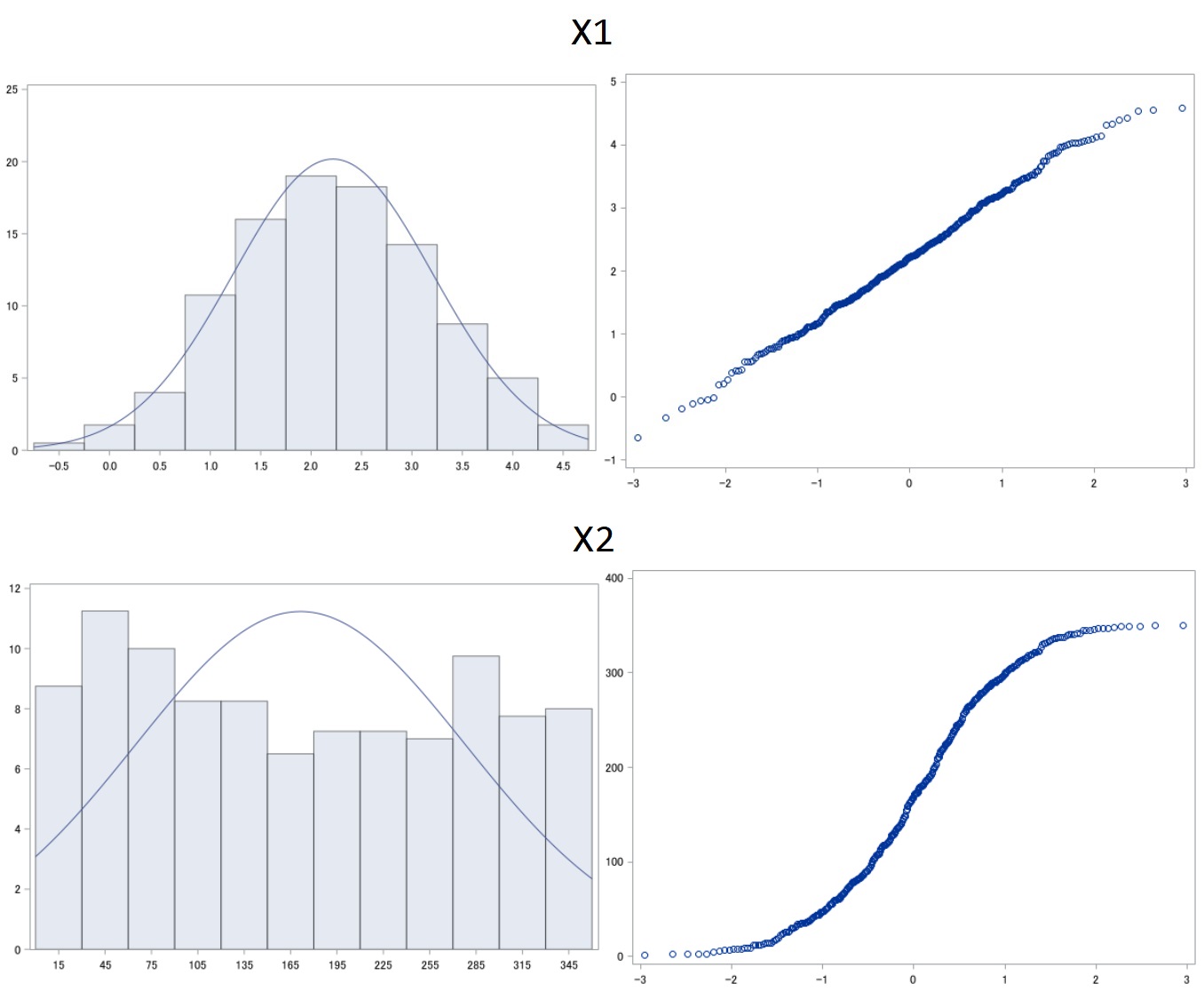
Ci-dessous les distributions et diagrammes quantile-quantile respectifs des deux variables. Nous constatons que x1 suit bien une distribution normale, ce qui n'est pas le cas de x2 :
proc univariate data=df ;
var x1 x2;
histogram x1 / Normal;
histogram x2 / Normal;
qqplot x1 / Normal;
qqplot x2 / Normal;
run;
Normalisons à présent les variables x1 et x2 en appliquant une transformation de type min/max :
proc stdize data=df method=range out=scaled_df ;
var x1 x2;
run;
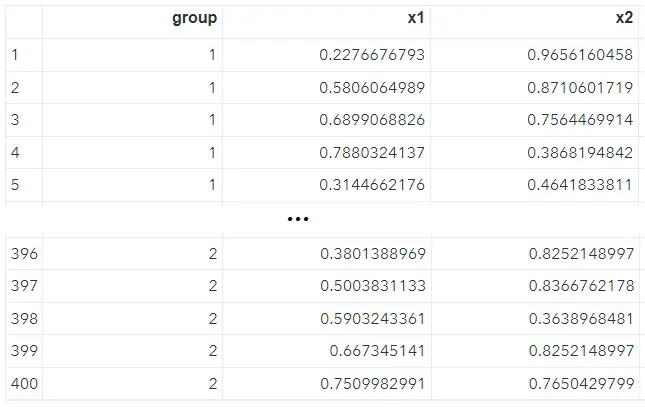
Nous pouvons noter plusieurs choses :
- la normalisation, à l'instar de la standardisation, s'effectue via une proc stdize. Seule la méthode indiquée en option
va varier. Nous avons ici spécifié l'option RANGE,
- nos variables sont bien comprises entre 0 et 1,
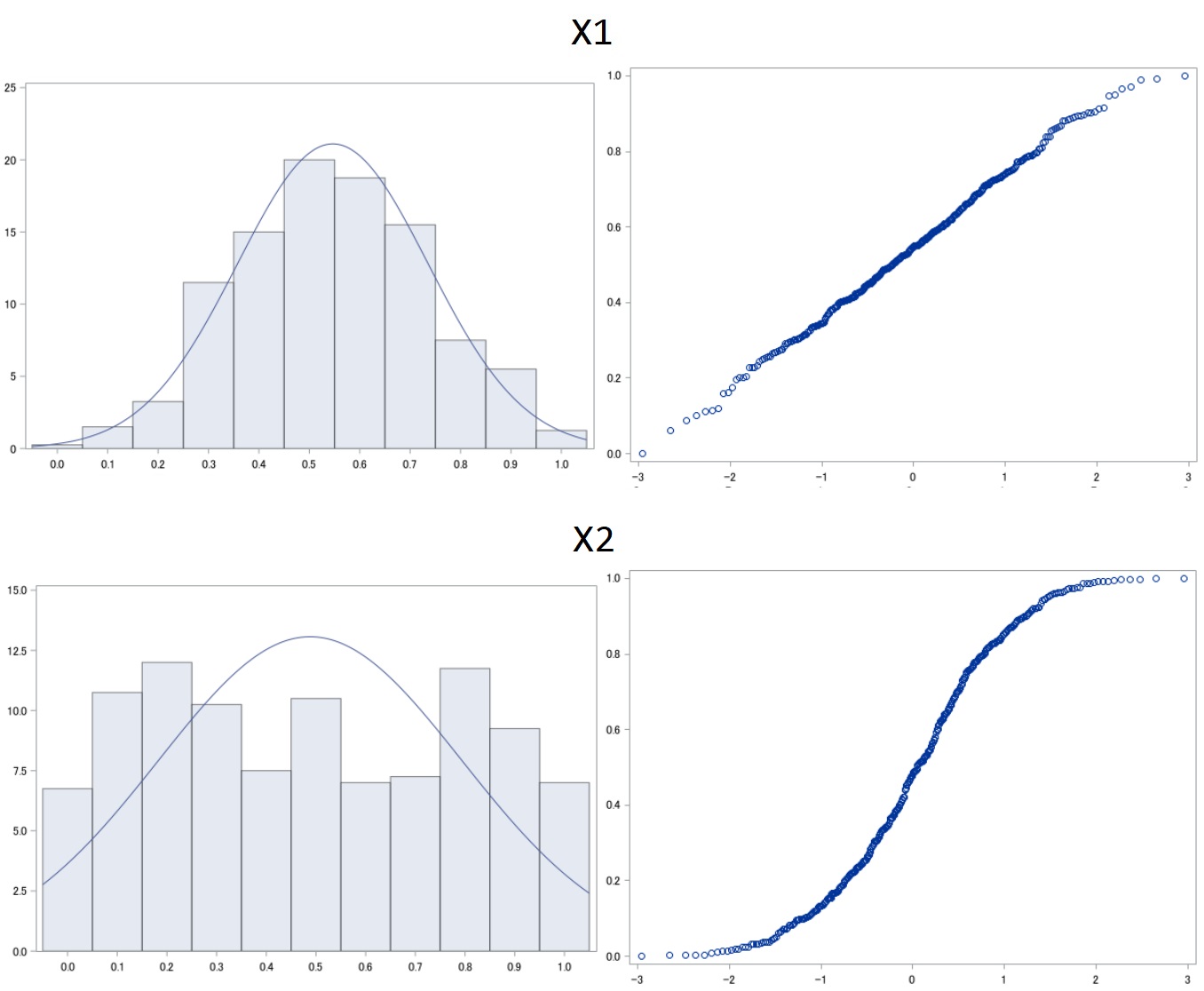
- comme nous le constatons ci-dessous, la normalité de la distribution x1 n'a pas été impactée par la transformation.
proc univariate data=scaled_df ;
var x1 x2;
histogram x1 / Normal;
histogram x2 / Normal;
qqplot x1 / Normal;
qqplot x2 / Normal;
run;
Normalisation par groupe
Il est tout à fait possible de procéder à une transformation sur la base d'un groupe, c'est à dire d'un sous-ensemble des observations, plutôt que sur la totalité du set de données. Dans notre exemple, une normalisation de la variable x1 sur la base du groupe va venir, pour le groupe 1 par exemple, centrer chaque valeur sur le minimum de x1 dans le groupe 1 puis réduire à l'étendue constatée au sein de celui-ci. Ci-dessous le code SAS permettant de normaliser par groupe :
proc stdize data=df method=range out=scaled_df ;
var x1 x2;
by group;
run;
Précisons que le regroupement est applicable quelle que soit la méthode de normalisation adoptée.
Normalisation robuste
La transformation min/max que nous venons de voir conserve les outliers, aussi, il est préférable de s'orienter vers
une normalisation dite robuste si l'objectif est d'atténuer les effets que les valeurs aberrantes d'une série pourraient
avoir sur le processus en aval.
Cette normalisation va venir centrer une variable sur sa médiane et réduire ensuite la valeur ainsi centrée en la
rapportant à l'écart interquartile (IQR), c'est à dire la différence entre le 3e et le 1er quartile.
$${x_{r} = \frac{X - mediane_{(X)}}{IQR}}$$
C'est également la proc stdize qui va nous permettre d'appliquer une normalisation robuste. L'option method prend dans ce cas la valeur iqr, comme ceci :
proc stdize data=df method=iqr out=robust_scaled_df ;
var x1 x2;
run;
Normalisation Z-score ou standardisation
A la lecture des méthodes précédentes, vous l'aurez compris : normaliser une variable consiste, en général, à la mettre
à l'échelle [0..1] en lui faisant subir deux opérations que sont le centrage et la réduction. La standardisation, que nous allons
aborder maintenant, consiste à centrer une variable sur sa moyenne et la réduire sur son écart-type. On obtient, par conséquent,
à l'issue de cette transformation, une variable de moyenne nulle et d'écart-type égal à 1. La standardisation est
également appelée normalisation Z-score.
Il est préférable d'appliquer une telle transformation sur des données dont on sait que la distribution suit une loi normale,
même si ce point n'est pas obligatoire. La standardisation est la méthode la plus couramment utilisée pour toute transformation
visant à mettre à l'échelle des données destinées à alimenter des algorithmes émettant l'hypothèse de normalité.
$${x_{s} = \frac{X - \mu}{\sigma}}$$
Ci-dessous, deux méthodes qui permettent d'obtenir le même résultat. Vous noterez que, dans la seconde, nous avons la main sur les paramètres de normalisation.
proc stdize data=df out=std_df1;
var x1 x2;
run;
proc standard data=df mean=0 std=1 out=std_df2;
var x1 x2;
run;
Une simple vérification nous permet de constater que, dans les deux cas, nous arrivons bien à une moyenne qui tend vers 0 et un écart-type égal à 1 :
proc means data=std_df1;
var x1 x2;
run;
proc means data=std_df2;
var x1 x2;
run;

Compléments
Finissons enfin en précisant qu'il existe une multitude de méthodes pour normaliser les données. La proc stdize possède un panel important de méthodes de calcul dont les spécifications sont bien détaillées sur l'aide en ligne et notamment sur cette page qui synthétise les méthodes implémentables : Standardization methods
Retrouvez dans la rubrique "Nos datasets" toutes les données dont vous aurez besoin pour tester et pratiquer !