

SQL sous SAS
Découvrez la proc SQL ou comment coder en SQL sous SAS
La proc SQL constitue une alternative à l'étape DATA, bien que tout le spectre de cette dernière ne soit pas entièrement couvert. La proc SQL permet néanmoins de basculer du compilateur SAS vers le compilateur SQL et ainsi d'avoir accès à un langage de requêtage puissant et bien connu de tous.
Nous allons, dans cet article, illustrer l'utilisation de la proc SQL et voir les bases pour l'implémenter sous SAS.
Données de travail
Nous allons requêter un dataset présent en standard dans SAS : sashelp.Fish
Il s'agit d'un jeu de données regroupant les caractéristiques de 159 poissons péchés
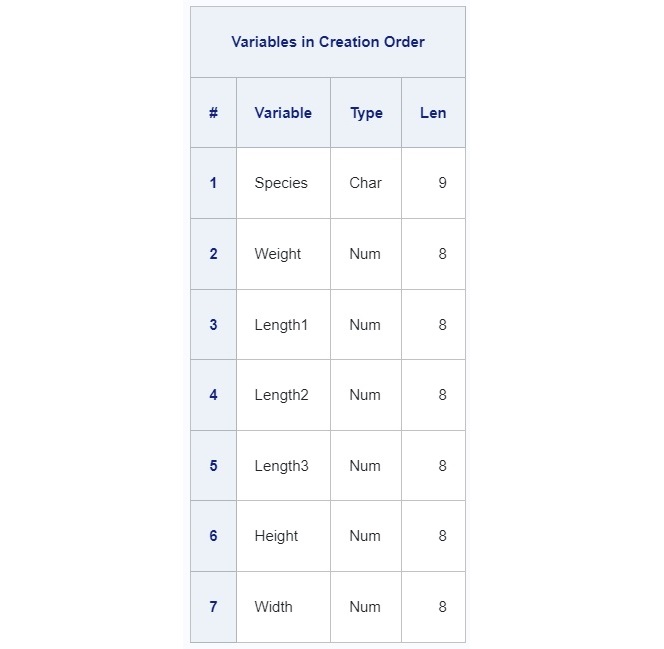
dans un lac Finlandais. Editons tout d'abord les métadonnées associées à ce dataset
afin d'identifier les colonnes sur lesquelles nous allons travailler.
proc contents data=sashelp.Fish;
run;
Sélection des données
Commençons par l'instruction SELECT. Voici ci-dessous comment nous allons sélectionner les données de notre table, tout d'abord, sans filtre d'aucune sorte :
proc sql;
select *
from sashelp.Fish;
quit;
Vous remarquez que la proc sql se termine non pas par l'instruction run mais quit. SAS va en effet basculer sur un compilateur SQL à la lecture de l'instruction proc sql puis revenir dans le compilateur SAS sur l'instruction quit. La requête SQL est typique d'une requête aux normes ANSI. Stipulons à présent des colonnes à conserver et, par la même occasion, précisons au compilateur de nous sortir uniquement les 5 premières observations : :
proc sql outobs=5;
select Species, Weight, Height
from sashelp.Fish;
quit;
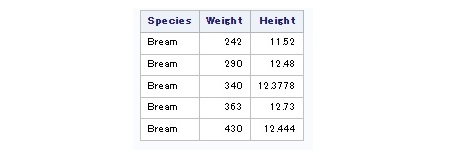
Vous constatez que l'instruction nous permettant de limiter les observations éditées est une option de la commande proc et non une instruction SQL comme TOP ou LIMIT par exemple.
Formatage des données
Sur la base de la requête précédente, nous allons formater la colonne Height afin de limiter le nombre de chiffres après la virgule. Pour cela deux possibilités :
proc sql outobs=5;
select Species, Weight, Height format 5.1
from sashelp.Fish;
quit;
ou, via l'instruction PUT associée à un alias :
proc sql outobs=5;
select Species, Weight, PUT(Height, 5.1) AS Height_formated
from sashelp.Fish;
quit;
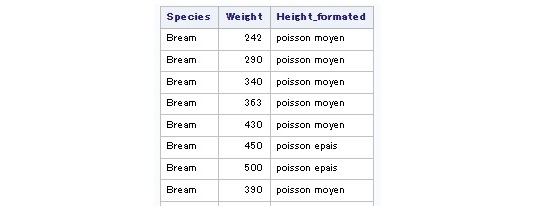
Notez que nous pouvons également utiliser les format utilisateur. Ci-dessous, nous allons par exemple regrouper les poissons par classe en établissant une correspondance des modalités via un format utilisateur :
PROC FORMAT ;
VALUE tailles
0 -< 10 = "poisson plat"
10 -< 13 = "poisson moyen"
13 - HIGH = "poisson epais"
;
RUN ;
proc sql;
select Species, Weight, PUT(Height, tailles.) as Height_formated
from sashelp.Fish;
quit;
Alias vs. Label
Nous avons vu, dans l'exemple précèdent, l'utilisation d'un alias. Il s'agit en fait du nom de la variable à laquelle on affecte le résultat de l'opération sur la colonne traitée. Dans notre cas, s'agissant d'un formatage, il y avait peu d'intérêt, mais cela prend tout son sens sur des opérations d'agrégation (SUM, MEAN, etc ...).
L'alias ne doit pas être confondu avec l'étiquette d'une colonne (Label) qui va simplement consister à donner une description à la colonne. Celle-ci sera éditée à la place de son nom technique mais c'est bien ce dernier qu'il faudra stipuler dans toute opération de sélection. L'exemple ci-dessous crée une nouvelle table FishV2 qui va être issue du calcul du poids moyen des poissons par espèce :
proc sql;
create table FishV2 As
select Species, mean(Weight) as average_weight format=5.1 label="Average weight"
from sashelp.Fish
group by Species;
quit;
Dans l'exemple ci-dessus, nous avons introduit une nouvelle instruction : create table. Celle-ci,
comme son nom l'indique, va venir créer une nouvelle table issue du résultat de l'instruction select
qui suit.
Dans notre requête, nous avons demandé l'espèce puis effectué la moyenne des poids en précisant un
alias average_weight, un formatage mais également un label. Au final, notre nouvelle table FishV2 va
compter 2 colonnes : Species et average_weight. Les valeurs associées à cette dernière seront stockées
sur la base du format indiqué.
Précisons enfin que, sans alias, SAS aurait généré un nom de colonne lui-même.
Clause WHERE
Les instructions SQL sous SAS sont identiques à ce que vous connaissez surement déjà, aussi nous n'allons pas nous éterniser sur ce point. Voici ci-dessous quelques exemples de conditions :
/*dont le poids est sup a 900*/
where Weight > 900
/*dont le poids est sup a 900 et la
longueur est inf ou egale a 38*/
where (Weight > 900) and (Length1 <= 38)
/*dont la diff entre la longueur 2 et
la longueur 1 est sup a 3*/
where (Length2 - Length1) > 3
/*dont le poids est compris entre 500
et 700*/
where Weight between 500 and 700
/*dont le nom de l'espece n'est ni
Bream ni Perch*/
where Species not in ("Bream", "Perch")
/*dont le poids est une valeur manquante
(null)*/
where Weight is null
/*dont le nom de l'espece commence par
un B*/
where Species like "B%"
/*dont le nom de l'espece est sur 5
caracteres et se termine par "ch" */
where Species like "___ch"
Sur la clause where précisons enfin que les opérateurs logiques and et or s'utilisent également tels que l'on a l'habitude de les implémenter :
proc sql;
select *
from sashelp.Fish
where Species like "___ch"
and (Weight < 300 or Weight > 500);
quit;
Agrégation et tri
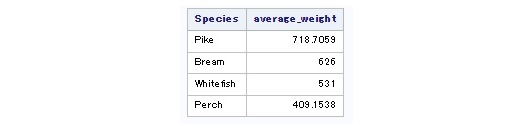
Nous allons ici dérouler un exemple qui porte sur les instruction group by, having et order. Nous avons déjà, dans une précédente requête illustré group by, nous allons donc ajouter avec having une sélection sur l'agrégation en cours.
Editons la liste des espèces dont le poids moyen est à supérieur ou égal à 400. Seuls les poissons longs de plus de 15 cm seront pris en compte. Enfin le tout sera trié par poids moyens décroissants.
proc sql;
select Species, mean(Weight) as average_weight
from sashelp.Fish
where Length1 > 15
group by Species
having average_weight >= 400
order by average_weight desc;
quit;
Création / modification de tables
Avant d'aborder les jointures, nous allons ouvrir une brève parenthèse sur la création et la modification de tables. Pour ce faire, nous allons effectuer deux taches : tout d'abord, créer une table maPeche qui va reprendre la table standard, mais à laquelle nous allons ajouter une colonne Id, nous permettant d'identifier chaque poisson de façon unique. Ensuite, nous allons créer une nouvelle table mesVentes qui va synthétiser les poissons vendus sur le port voisin. Allons-y !
Il existe un compteur bien pratique accessible depuis l'étape data : _n_. Il s'agit d'une variable qui contient l'incrément courant de l'exécution en cours. Malheureusement, celle-ci n'est pas accessible depuis une proc sql, aussi il faut se tourner vers une fonction monotonic() qui va nous permettre de générer une colonne de nombre. Nous allons dans l'exemple qui suit créer une table maPeche en copie de la table standard sashelp.Fish puis y insérer une nouvelle colonne Id. Enfin, à l'aide de la fonction monotonic(), nous allons peupler cette colonne avec un indice incrémental :
proc sql;
/*Creation de la table MaPeche par copie*/
create table maPeche as
select *
from sashelp.Fish;
/*Ajout d'une colonne Id*/
alter table maPeche
add id num;
/*Initialisation de l'Id*/
update maPeche
set Id=monotonic();
/*Edition du contenu*/
select *
from maPeche;
quit;
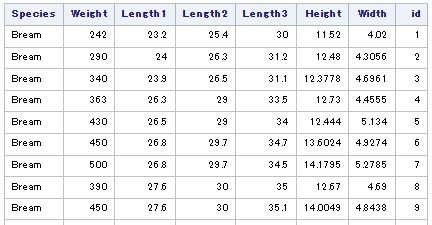
Ceci étant fait, nous allons désormais créer une nouvelle table de toute pièce en spécifiant les colonnes et leur type respectif, puis en alimentant celles-ci via des valeurs :
proc sql;
/*Creation de la table mesVentes*/
create table mesVentes
(Id num, /* Id du poisson */
Price num); /* prix de vente */
/*Insertion des valeurs*/
insert into mesVentes
set Id=2,
Price=5
set Id=4,
Price=7
set Id=5,
Price=8
set Id=10,
Price=12
set Id=11,
Price=8
set Id=14,
Price=7;
/*Edition du contenu*/
select *
from mesVentes;
quit;
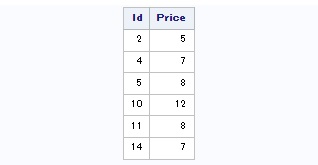
Vous l'aurez peut-être déjà compris, outre le fait d'illustrer la création et modification de tables, nous avons fait tout ceci dans le but d'avoir de la matière pour travailler sur les jointures. C'est l'objet du point suivant !
Jointures
On distingue quatre types de jointures :
- jointure interne : dite INNER JOIN, seules les observations communes aux deux tables sont retenues,
- jointure externe : dite OUTER JOIN ou également FULL JOIN, toutes les observations sont prises en comptes. Celles qui n'ont pas de correspondance dans la table jointe ressortent avec des colonnes à NULL,
- jointure gauche : dite LEFT JOIN, toutes les observations de la première table et seulement celles-ci sont retenues. Celles pour lesquelles une correspondance avec la table jointe a été trouvée voient leurs informations complétées, les autres ressortent à NULL,
- jointure droite : dite RIGHT JOIN, il s'agit du même principe qu'énoncé précédemment, mais pour la seconde table.
Pour illustrer nos propos, éditons dans un premier temps les poissons pêchés puis vendus, via une jointure interne :
proc sql;
select T1.Id, T1.species, T2.Price
from maPeche as T1 inner join mesVentes as T2
on T1.Id = T2.Id;
quit;
Vous pouvez noter que nous avons spécifié un alias pour nos tables dans le but de lever toute ambiguïté sur la colonne Id qui, en effet, porte le même nom dans les deux tables. Cette colonne Id, identifiant unique de chaque poisson, nous sert de pivot pour effectuer la jointure entre maPeche et mesVentes. Voici le résultat :
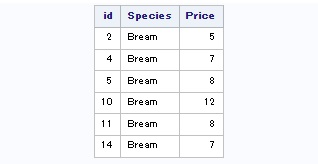
Editons à présent une jointure externe pour constater la différence :
proc sql;
select T1.Id, T1.species, T2.Price
from maPeche as T1 full join mesVentes as T2
on T1.Id = T2.Id;
quit;
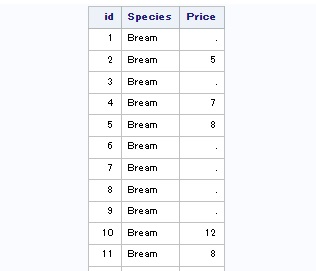
Seuls quelques observations ont été éditées sur cette illustration mais vous comprenez bien la logique.
Vues SQL
Depuis une proc sql, il est possible de sauvegarder une requête sous la forme d'une vue. A la différence d'une table, celle-ci ne contient pas de données à proprement parlé, il est donc impossible d'effectuer des opérations de création d'observations ou d’altération. Il s'agit, en quelque sorte, d'une sauvegarde de la requête elle-même. Voyons comment procéder puis déroulons une proc univariate sur celle-ci :
proc sql;
create view maVue as
select *
from sashelp.Fish
where Species like "___ch"
and (Weight < 300 or Weight > 500);
quit;
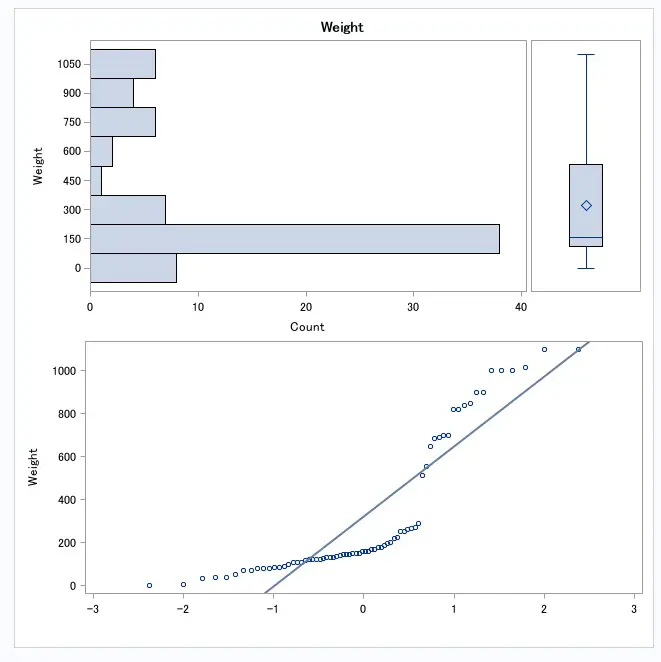
proc univariate data=work.maVue normal plots;
var weight;
run;
Nous avons ci-dessus repris une requête vue précédemment. Celle-ci a été sauvegardée sous la forme d'une vue, nommée maVue. Suite à la proc sql, nous avons implémenté une proc univariate sur la colonne Weigth, voici le résultat :
Crédits
Miniature issue de vecstock sur Freepik
Retrouvez dans la rubrique "Nos datasets" toutes les données dont vous aurez besoin pour tester et pratiquer !