
L'algorithme ID3
La référence de la classification supervisée
Développé par l'un des pionniers de la théorie de la décision Ross Quinlan, ID3 reste une référence dans le domaine de la classification à base d'arbres de décision. Cet article se propose de présenter en détail cet algorithme fondateur et de le dérouler pas à pas sur un exemple concret.
Classification supervisée
Un processus de classification a pour but, comme son nom l'indique, d'attribuer à une observation une classe. Par classe, il faut comprendre catégorie. Il s'agit en effet d'associer l'observation à une des modalités de la variable catégorielle cible. Pour ce faire, le processus de classification va se baser sur les caractéristiques, ou attributs, des observations. Cet ensemble de variables explicatives constitue le corpus d'étude.
Les données du corpus d'étude peuvent être étiquetées ou non. Dans le premier cas on parlera d'un processus d'apprentissage dit supervisé au cours duquel il s'agira d'attribuer une classe, connue à priori, à une observation en se basant sur les similitudes observées dans le corpus d'étude. A l'inverse, lors d'un processus d'apprentissage non supervisé, il s'agira de déceler une structure dans le corpus d'étude pour en déduire des groupes dont les modalités ne sont pas connues.
Arbres de décision
L'arbre de décision constitue un outil employé principalement dans l'aide à la décision ou l'exploration de
données. L'imbrication des branches conditionnelles lui vaut son nom. Un arbre de décision, lorsqu'il est
employé comme méthode d'apprentissage concerne principalement la classification.
Une arbre de décision est essentiellement constitué :
- de nœuds non terminaux représentant les tests sur les variables explicatives, ou attributs,
- de branches portant les valeurs, nécessairement discrètes, des variables explicatives,
- de nœuds terminaux représentant la classification résultante.
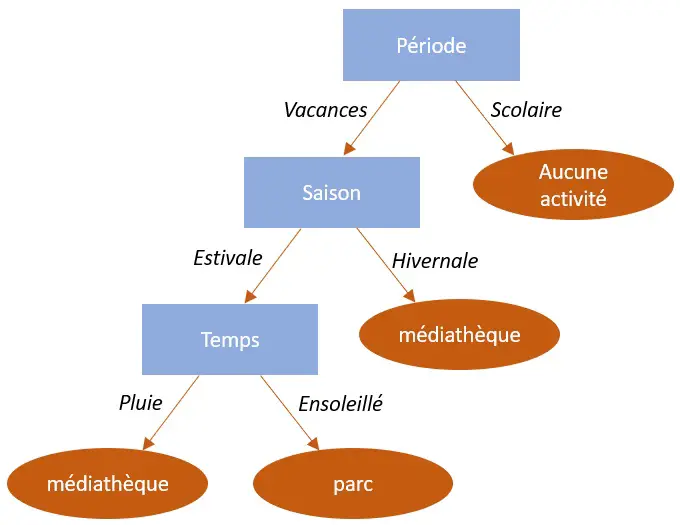
Ci-dessous un exemple d'arbre de décision. Il s'agit en l'occurrence du choix d'une activité pour un centre de loisirs. Comme vous le constatez, 3 attributs permettent ici la prise de décision (la période, la saison et le temps qu'il fait).
Vocabulaire
Nous emploierons dans cet article le terme attributs pour designer les caractéristiques de l'observation. Il s'agit
de l'ensemble des variables explicatives qui vont permettre de construire l'arbre de décision. Chaque attribut a
un nombre fini de valeurs, aussi, tout attribut quantitatif continu devra au préalable être discrétisé.
L'objet de l'arbre est d'associer une observation à une classe. La classe est donc une modalité de la variable
d'intérêt. Cette variable d'intérêt constitue ce que l'on appelle également la fonction objectif. C'est précisément
cet attribut particulier qui fera office d'élément discriminant.
Principe de l'algorithme
ID3 signifie "Iterative Dichotomiser 3". Comme son nom le laisse à penser, cet algorithme va diviser de manière récursive le jeu de données pour procéder à la construction de l'arbre de décision. Ce principe est général aux algorithmes traitant des arbres. La différence réside principalement dans le métrique utilisé pour sélectionner l'attribut discriminant.
Concrètement, ID3 agit ainsi :
Etape 1 : Il sélectionne l'attribut discriminant dans le jeu de données,
Etape 2 : Un sous-ensemble du jeu de données est constitué sur la base de chaque valeur possible de l'attribut sélectionné,
Etape 3 : L'algorithme retourne a l'étape 1 pour chaque sous-ensemble généré lors l'étape précédente.
Choix de l'attribut discriminant
A chaque itération, ID3 choisit, dans le corpus d'étude qui lui est soumis, l'attribut le plus discriminant. Il faut comprendre par là, l'attribut qui va lui permettre de scinder de la façon la plus pertinente possible le corpus d'étude. Pour cela, ID3 utilise la notion d'entropie. Il faut considérer l'entropie comme un métrique pour quantifier l'information portée par l'attribut.
ID3 va tout d'abord quantifier l'information portée par la variable d'intérêt dans l'ensemble de données qu'il lui est soumis, puis comparer l'entropie ainsi obtenue à celle de chaque sous-ensemble issu de la division sur les attributs. Nous appellerons cette comparaison la fonction de gain, l'attribut dont la fonction de gain sera la plus élevée constituera l'attribut portant le plus d'information et donc, le plus discriminant.
Définissons l'entropie à présent :
Soit :
\(E\) : Le corpus d'étude,
\(H_{(E)}\) : L'entropie du corpus d'étude,
\(C\) : L'ensemble des modalités de la variable d'intérêt,
\(P(c)\) : La proportion que représente les observations associées à la classe c dans le corpus d'étude.
L'entropie du corpus d'étude soumis a l'algorithme est telle que :
$${H_{(E)} = \sum_{c \in C} -P(c). log_{2}P(c)}$$
De même, définissons la fonction de gain :
Soit :
\(A\) : L'attribut à tester,
\(F_{(A, E)}\) : La fonction de gain de l'attribut A dans le corpus d'étude E,
\(S_{/A}\) : Les sous-ensembles issus de la division du corpus d'étude E par l'attribut A,
La fonction de gain de l'attribut A dans le corpus d'étude E est telle que :
$${F_{(A, E)} = H_{(E)} - \bar{H}_{(A)}}$$
où
$${\bar{H}_{(A)} = \sum_{s \in S_{/A}} -P(s). log_{2}P(s)}$$
Application
Nous allons prendre pour exemple d'application de l'algorithme ID3 le cas d'une banque qui
doit décider d'accorder ou non un prêt immobilier à ses clients. Elle se base pour cela sur
3 critères : la situation professionnelle, la présence d'un apport personnel et enfin le fait
que le client ait déjà des crédits en cours.
Le jeu de données compte 20 individus, voici ci-dessous les données brutes :
| Individu | Situation | Apport personnel | Crédits en cours | Accord prêt |
|---|---|---|---|---|
| 1 | CDI | oui | oui | oui |
| 2 | CDI | oui | oui | oui |
| 3 | CDI | oui | oui | oui |
| 4 | CDI | oui | non | oui |
| 5 | CDI | non | non | oui |
| 6 | fonctionnaire | oui | non | oui |
| 7 | CDI | non | oui | oui |
| 8 | CDI | oui | oui | oui |
| 9 | fonctionnaire | oui | oui | oui |
| 10 | fonctionnaire | non | non | oui |
| 11 | CDD | non | oui | non |
| 12 | CDD | non | non | oui |
| 13 | CDD | oui | oui | non |
| 14 | sans emploi | oui | non | non |
| 15 | CDD | non | non | oui |
| 16 | sans emploi | non | oui | non |
| 17 | CDI | oui | oui | oui |
| 18 | sans emploi | non | non | non |
| 19 | sans emploi | non | oui | non |
| 20 | CDD | oui | non | oui |
Première itération
Nous commençons par calculer l'entropie pour l'échantillon. La variable d'intérêt, en l'occurrence, l'accord du prêt, présente deux modalités : oui et non. Chacune de ces deux classes représente respectivement 14/20 et 6/20 des clients. Nous avons donc l'entropie suivante :
$${H_{(E)} = -P(oui). log_{2}P(oui) -P(non). log_{2}P(non)}$$ $${H_{(E)} = -(14/20). log_{2}(14/20) -(6/20). log_{2}(6/20)}$$ $${H_{(E)} = 0.36 + 0.52 = 0.88}$$
Via la fonction de gain, comparons a présent cette entropie avec celle des sous-ensembles issus de la division par les attributs. Notre objectif étant de trouver l'attribut qui porte le plus d'information, le plus discriminant :
Attribut "Situation", détails des calculs
L'attribut "Situation" présente 4 modalités (CDI, CDD, fonctionnaire et sans emploi). Voici l'entropie portée par les sous-ensembles issus de chaque modalité : $${H_{(Situation = CDI)} = -(8/8). log_{2}(8/8) -(0/8). log_{2}(0/8) = 0}$$ $${H_{(Situation = CDD)} = -(3/5). log_{2}(3/5) -(2/5). log_{2}(2/5) = 0.97}$$ $${H_{(Situation = fonctionnaire)} = -(3/3). log_{2}(3/3) -(0/3). log_{2}(0/3) = 0}$$ $${H_{(Situation = sans emploi)} = -(0/4). log_{2}(0/4) -(4/4). log_{2}(4/4) = 0}$$
L'entropie moyenne portée par l'attribut "Situation" peut donc être résumée ainsi : $${\bar{H}_{(Situation)} = P(CDI) * H_{(Situation = CDI)} + P(CDD) * H_{(Situation = CDD)} + P(fonctionnaire) * H_{(Situation = fonctionnaire)} + P(sans emploi) * H_{(Situation = sans emploi)}}$$ $${\bar{H}_{(Situation)} = 8/20 * 0 + 5/20 * 0.97 + 3/20 * 0 + 4/20 * 0}$$ $${\bar{H}_{(Situation)} = 0.24}$$
Pour l'attribut Situation, la fonction de gain qui en résulte est donc : $${F_{(Situation, E)} = H_{(E)} - \bar{H}_{(Situation)}}$$ $${F_{(Situation, E)} = 0.88 - 0.24}$$ $${F_{(Situation, E)} = 0.64}$$
Synthèse des fonctions de gains par attribut
Les calculs effectués ci-dessus pour l'attribut "Situation" ont été réalisés pour les 2 autres : "Apport personnel" et "Crédits en cours". Voici, dans le tableau ci-dessous, les fonctions de gain qui en résultent :
| Attribut | Fonction de gain |
|---|---|
| Situation | 0.64 |
| Apport personnel | 0.06 |
| Crédit en cours | 0.02 |
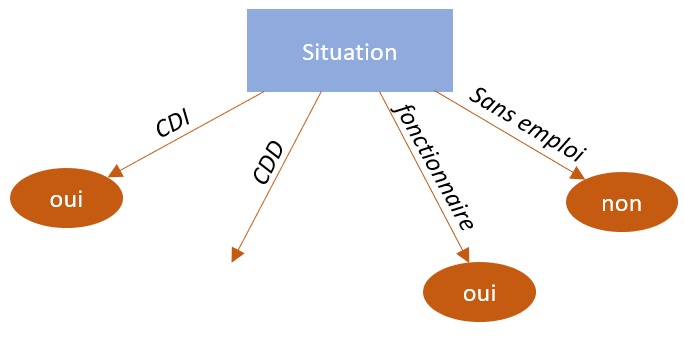
Il ressort de la première itération 2 choses. Tout d'abord, l'attribut "Situation" constitue l'attribut le plus discriminant. Dans la logique de l'algorithme ID3, nous allons donc retenir celui-ci pour créer notre premier nœud. Par ailleurs, l'entropie portée par les modalités CDI, fonctionnaire et sans emploi est de 0, ce qui signifie qu'il n'y a pas d'information à analyser, ces branches peuvent être terminées par une classification définitive.
Seconde itération
A la vue de notre arbre de décision, nous constatons que la seconde itération va consister à partir d'un corpus d'étude constitué des clients en CDD uniquement (5 individus). Nous n'avons bien entendu qu'à nous soucier de deux attributs, l'apport personnel et la présence de crédits en cours.
Commençons par calculer l'entropie pour le sous échantillon constitué des clients en CDD :
$${H_{(E)} = -P(oui). log_{2}P(oui) -P(non). log_{2}P(non)}$$ $${H_{(E)} = -(3/5). log_{2}(3/5) -(2/5). log_{2}(2/5) = 0.97}$$
Via la fonction de gain, comparons à présent cette entropie avec celle des sous-ensembles issus de la division par les attributs restants afin d'en dégager le plus discriminant :
Attribut "Apport personnel", détails des calculs
L'attribut "Apport personnel" présente 2 modalités (oui et non). Voici l'entropie portée par les sous-ensembles issus de chaque modalité : $${H_{(Apport = oui)} = -(1/2). log_{2}(1/2) -(1/2). log_{2}(1/2) = 1}$$ $${H_{(Apport = non)} = -(2/3). log_{2}(2/3) -(1/3). log_{2}(1/3) = 0.92}$$
L'entropie moyenne portée par l'attribut "Apport personnel", pour les clients en CDD, peut donc être résumée ainsi : $${\bar{H}_{(Apport)} = P(oui) * H_{(Apport = oui)} + P(non) * H_{(Apport = non)}}$$ $${\bar{H}_{(Apport)} = 2/5 * 1 + 3/5 * 0.92}$$ $${\bar{H}_{(Apport)} = 0.95}$$
Pour l'attribut "Apport personnel", la fonction de gain qui en résulte est donc : $${F_{(Apport, E)} = H_{(E)} - \bar{H}_{(Apport)}}$$ $${F_{(Apport, E)} = 0.97 - 0.95}$$ $${F_{(Apport, E)} = 0.02}$$
Synthèse des fonctions de gains par attribut
Les calculs effectués ci-dessus pour l'attribut "Apport" ont été réalisés pour le dernier attribut "Crédit en cours". Voici, dans le tableau ci-dessous, une synthèse des fonctions de gain calculées :
| Attribut | Fonction de gain |
|---|---|
| Apport personnel | 0.02 |
| Crédit en cours | 0.97 |
Il ressort de la seconde itération que l'attribut "Crédit en cours" constitue l'attribut le plus discriminant pour les clients en CDD. Nous allons donc retenir celui-ci pour créer notre second nœud. Par ailleurs, l'entropie portée par chacune des modalités de cet attribut sont nulles, les branches vont donc pouvoir être terminées par une classification définitive.
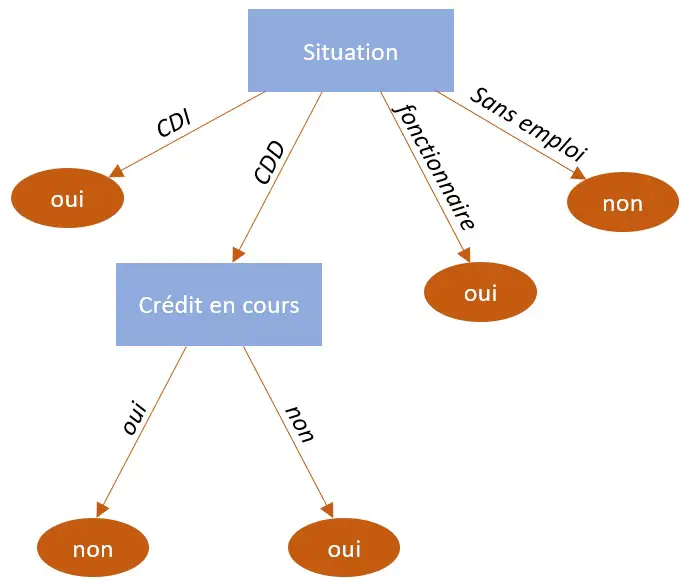
En l'état, sur cet échantillon, l'attribut "apport personnel" n'a aucune influence dans la prise de décision.
Conclusion
Nous venons de voir l'algorithme ID3. Il se révèle relativement simple à comprendre. ID3 est ce que l'on appelle un algorithme glouton. A ce titre, il procède par étape et choisit à chacune d'entre elles un optimum local. Par conséquent, bien qu'il soit simple à mettre en œuvre, il n'est pas certain, au final, d'aboutir à un arbre optimal.
Crédits
Illustration arbre, Image de macrovector sur Freepik
Retrouvez dans la rubrique "Nos datasets" toutes les données dont vous aurez besoin pour tester et pratiquer !